Forward-fill missing data in Spark
Posted on Fri 22 September 2017 • 4 min read
Since I’ve started using Apache Spark, one of the frequent annoyances I’ve come up against is having an idea that would be very easy to implement in Pandas, but turns out to require a really verbose workaround in Spark. Such is the price of scalability. But that does make it extra satisfying when I do manage to get done what I’m trying to do.
A recent example of this is doing a forward fill: filling null values with the last known non-null value, leaving leading nulls alone. In Pandas, this is very easy. I used it in my recent post about efficiently finding the time since the last event in a time series. This post is basically an explanation of this StackOverflow answer on doing forward fills with PySpark.
Imagine you are measuring the temperature in two spots in your back yard, one in the shade and one in the sun. You record a measurement every half hour so you can compare them. However, you got the cheapest possible digital thermometer, so a lot of the measurements end up missing. Your data may look something like this:
df
| time | location | temperature | |
|---|---|---|---|
| 0 | 2017-09-09 12:00:00 | shade | 18.830184 |
| 1 | 2017-09-09 12:00:00 | sun | NaN |
| 2 | 2017-09-09 12:30:00 | shade | NaN |
| … | … | … | … |
| 189 | 2017-09-11 11:00:00 | sun | 17.595510 |
| 190 | 2017-09-11 11:30:00 | shade | NaN |
| 191 | 2017-09-11 11:30:00 | sun | 18.630506 |
192 rows × 3 columns
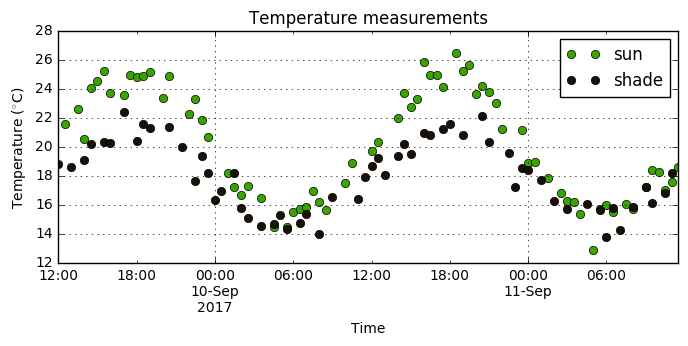
To compare the measurements each half hour (or maybe to do some machine learning), we need a way of filling in the missing measurements. If the value we are measuring (in this case temperature) changes slowly with respect to how frequently we make a measurement, then a forward fill may be a reasonable choice.
In Pandas, this is easy. We just do a groupby without aggregation, and to each group apply the .fillna method, specifying specifying method='ffill', also known as method='pad':
df_filled = df.groupby('location')\
.apply(lambda group: group.fillna(method='ffill'))
df_filled
| time | location | temperature | |
|---|---|---|---|
| 0 | 2017-09-09 12:00:00 | shade | 18.830184 |
| 1 | 2017-09-09 12:00:00 | sun | NaN |
| 2 | 2017-09-09 12:30:00 | shade | 18.830184 |
| … | … | … | … |
| 189 | 2017-09-11 11:00:00 | sun | 17.595510 |
| 190 | 2017-09-11 11:30:00 | shade | 18.226763 |
| 191 | 2017-09-11 11:30:00 | sun | 18.630506 |
192 rows × 3 columns
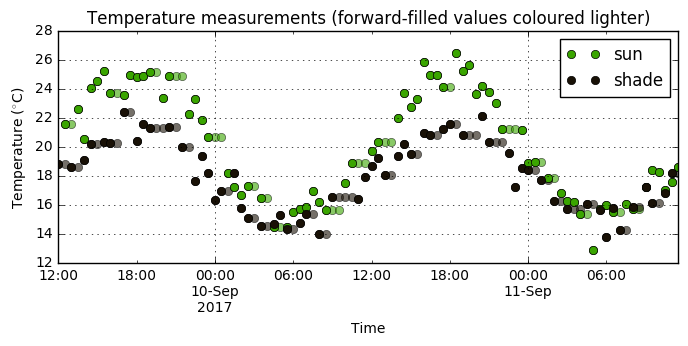
We can see the effect this had on the data by plotting. We hope to end up with nice, regular measurements without having distorted the overall shape too much:
In Spark, things get a bit trickier. The key ingredients are:
-
The
pyspark.sql.Windowobject. A window, which may be familiar if you use SQL, acts kind of like a group in a group by, except it slides over the data, allowing you to more easily return a value for every row (instead of doing an aggregation). A window is specified in PySpark with.rowsBetween, which takes the indices of the rows to include relative to the current row (where the value will be returned in the output). The rows in the window can be ordered using.orderBy, and partitioned using.partitionBy. Partitioning over a column ensures that only rows with the same value of that column will end up in a window together, acting similarly to a group by. -
The
pyspark.sqlwindow functionlast. As its name suggests,lastreturns the last value in the window (implying that the window must have a meaningful ordering). It takes an optional argumentignorenullswhich, when set toTrue, causeslastto return the last non-nullvalue in the window, if such a value exists.
The strategy to forward fill in Spark is as follows. First we define a window, which is ordered in time, and which includes all the rows from the beginning of time up until the current row. We achieve this here simply by selecting the rows in the window as being the rowsBetween -sys.maxint (the largest negative value possible), and 0 (the current row). Specifying too large of a value for the rows doesn’t cause any errors, so we can just use a very large number to be sure our window reaches until the very beginning of the dataframe. If you need to optimize memory usage, you can make your job much more efficient by finding the maximal number of consecutive nulls in your dataframe and only taking a large enough window to include all of those plus one non-null value. We partition the window by the location column to make sure that gaps only get filled with previous measurements from the same location.
We act with last over the window we have defined, specifying ignorenulls=True. If the current row is non-null, then the output will just be the value of current row. However, if the current row is null, then the function will return the most recent (last) non-null value in the window.
For a Spark dataframe with the same data as we just saw in Pandas, the code looks like this:
# the same data as before
spark_df.show(10)
+-------------------+--------+------------------+
| time|location| temperature|
+-------------------+--------+------------------+
|2017-09-09 12:00:00| shade|18.830184076113213|
|2017-09-09 12:00:00| sun| null|
|2017-09-09 12:30:00| shade| null|
|2017-09-09 12:30:00| sun| 21.55237663805009|
|2017-09-09 13:00:00| shade| 18.59059750682235|
|2017-09-09 13:00:00| sun| null|
|2017-09-09 13:30:00| shade| null|
|2017-09-09 13:30:00| sun|22.587784977960474|
|2017-09-09 14:00:00| shade|19.101003724324197|
|2017-09-09 14:00:00| sun|20.548896316341516|
+-------------------+--------+------------------+
only showing top 10 rows
from pyspark.sql import Window
from pyspark.sql.functions import last
# define the window
window = Window.partitionBy('location')\
.orderBy('time')\
.rowsBetween(-sys.maxsize, 0)
# define the forward-filled column
filled_column = last(spark_df['temperature'], ignorenulls=True).over(window)
# do the fill
spark_df_filled = spark_df.withColumn('temp_filled_spark', filled_column)
# show off our glorious achievements
spark_df_filled.orderBy('time', 'location').show(10)
+-------------------+--------+------------------+------------------+
| time|location| temperature| temp_filled_spark|
+-------------------+--------+------------------+------------------+
|2017-09-09 12:00:00| shade|18.830184076113213|18.830184076113213|
|2017-09-09 12:00:00| sun| null| null|
|2017-09-09 12:30:00| shade| null|18.830184076113213|
|2017-09-09 12:30:00| sun| 21.55237663805009| 21.55237663805009|
|2017-09-09 13:00:00| shade| 18.59059750682235| 18.59059750682235|
|2017-09-09 13:00:00| sun| null| 21.55237663805009|
|2017-09-09 13:30:00| shade| null| 18.59059750682235|
|2017-09-09 13:30:00| sun|22.587784977960474|22.587784977960474|
|2017-09-09 14:00:00| shade|19.101003724324197|19.101003724324197|
|2017-09-09 14:00:00| sun|20.548896316341516|20.548896316341516|
+-------------------+--------+------------------+------------------+
only showing top 10 rows
Success! Note that a backward-fill is achieved in a very similar way. The only changes are:
-
Define the window over all future rows instead of all past rows:
.rowsBetween(-sys.maxsize,0)becomes.rowsBetween(0,sys.maxsize) -
Use
firstfrompyspark.sql.functionsinstead oflast.
That’s it! Happy filling!